Shopping Cart Recommendation
Monitoring Biases in a Recommender System
Step 1: Train the model
x_train_sku = [[e['product_sku'] for e in s] for s in data['x_train']]
model = Word2Vec(sentences=x_train_sku, vector_size=48, epochs=15).wvStep 2: Define a custom monitor (cosine distance between embeddings of predicted and selected items)
def cosine_dist_init(self):
self.cos_distances = []
self.model = model
def cosine_distance_check(self, inputs, outputs, gts=None, extra_args={}):
for output, gt in zip(outputs, gts):
if (not output) or (not gt):
continue
y_preds = output[0]
y_gt = gt[0]
try:
vector_test = self.model.get_vector(y_gt['product_sku'])
except:
vector_test = []
vector_pred = self.model.get_vector(y_preds)
if len(vector_pred)>0 and len(vector_test)>0:
cos_dist = cosine(vector_pred, vector_test)
self.cos_distances.append(cos_dist)
self.log_handler.add_histogram('cosine_distance', self.cos_distances, self.dashboard_name)Step 3: Define another custom monitor (price difference between predicted and selected items)
Step 4: Define the prediction pipeline
Step 5: Define UpTrain config and initialize the framework
Step 6: Ship your model in production with UpTrain
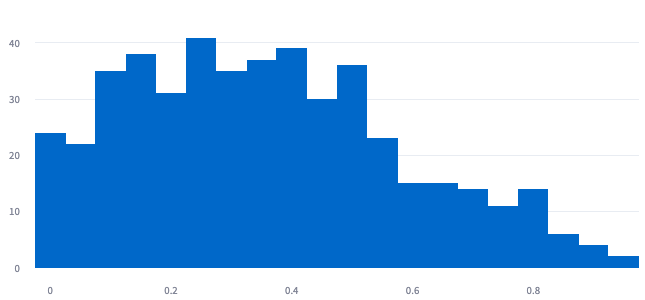
Histogram plot for items with popularity
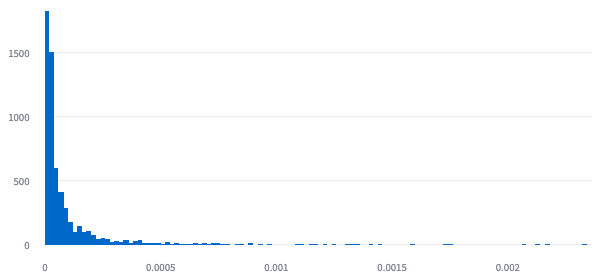
Histogram plot for cosine distance between ground truth and prediction
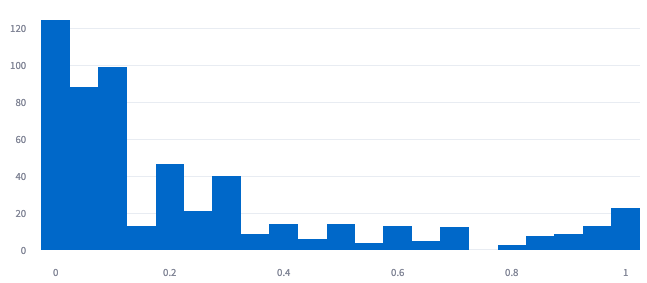
Histogram plot for absolute log price ratio between prediction and selected items
Last updated
Was this helpful?