Finetuning LLMs
Fine-tune a Large Pre-trained Language Model such as BERT
Overview: In this example, we will see how to fine-tune a large pre-trained language model such as BERT for the task of masked language modelling. Masked language modelling involves masking a certain percentage of tokens or words in a sentence and training the model to predict the masked tokens. Fine-tuning involves further training the pre-trained model on a specific task such as sentiment analysis or question-answering by adjusting the model's parameters to fit the specific task's requirements. We will use UpTrain to filter our dataset to make our data match specific conditions as defined in the problem statement.
Why is fine-tuning needed: Pre-trained language models, such as GPT-2 and BERT, are trained on large amounts of text data, which makes them very powerful. However, they are trained on generic tasks and may not be optimized for specific tasks. Fine-tuning the pre-trained model on a specific task, such as sentiment analysis or question-answering, allows the model to adapt to the task's specific requirements, resulting in improved performance. This makes fine-tuning essential to achieve optimal results on a specific NLP task.
Problem: In this example, we aim to generate positive sentiment predictions for a given text with masked words such as "Nike shoes are very [MASK]". The challenge is to ensure that the predicted words have a positive connotation, such as "Comfortable", "Durable", or "Good-looking". Conversely, negative sentiment words like "Expensive", "Ugly", or "Dirty" must not be predicted, as they may lead to inaccurate or undesired results. Thus, the goal is to achieve accurate predictions of masked words with a positive sentiment, while avoiding negative sentiment predictions that could affect the overall performance of the model.
Solution: We will be using UpTrain framework, which provides an easy-to-use technique for defining customized signals that make the process of data filtering less tedious. Data Integrity checks can also be applied to remove null-valued data. We make use of 🤗 Trainer API to perform fine-tuning on our pretrained model
Install Required packages
PyTorch: Deep learning framework.
Hugging Face Transformers: To use pretrained state-of-the-art models.
Hugging Face Datasets: Use public Hugging Face datasets
IPywidgets: For interactive notebook widgets
Import all required libraries
Model and Testing Data Setup
Define few cases to test our model performance before and after retraining.
testing_texts = [
"Nike shoes are very [MASK]",
"Nike atheletic wear is known for being very [MASK]",
"Nike [MASK] shoes are very comfortable",
"Trousers and Hoodies made by [MASK] are not very expensive",
"Nike tshirts are famous for being [MASK]"
]Initialize the model and tokenizer from the distilbert-base-uncased model
Let's visualize the model structure to understand the complexity behind these large language models
Take a look at the outputs of the vanilla distilbert-base-uncased model on predicting the outputs for the masked sentence:
"Nike shoes are very [MASK]"
Notice that we get the output "expensive" among the top 5 predictions. We want to fine-tune the model so that the predicted words form sentences that have a positive sentiment.
Dataset Usage/Synthesis
For this task, we can use datasets that are available online, synthesize our own datasets or use a combination of the two. To demonstrate the functionality of UpTrain, synthesizing our own dataset will do.
In the dataset synthesis, we generate two forms of sentences that we want to fine-tune the model on. Refer to the function definition of create_sample_dataset. Note that some sentences that will be formed may not make complete sense but that is not very relevant.
UpTrain Initialization and Retraining Dataset Generation
Define helper functions that UpTrain will use to detect edge cases which the model will fine-tune on instead of using the entire dataset.
nike_text_present_func: Checks for the existence of "nike" in a sentencenike_product_keyword_func: Checks if the sentence contains a product that is manufactured by Nikeis_positive_sentiment_func: Checks if a sentence has positive sentiment
Define the UpTrain Framework configuration
Filter out the data that we want to specifically fine-tune on as defined by the configuration provided above
Finetune the Model
We can see from the above output that the model is doing much better at predicting masked words that have positive sentiment associated with them.
In the first example, we see that the model no longer predicts masked words such as "expensive" among its top 5 predictions, which is exactly what we want!
An interesting case to look at is the predictions for example 3. We no longer have swim shoes! 😂
Visualizing Loss, Perplexity and Mask Prediction Confidence
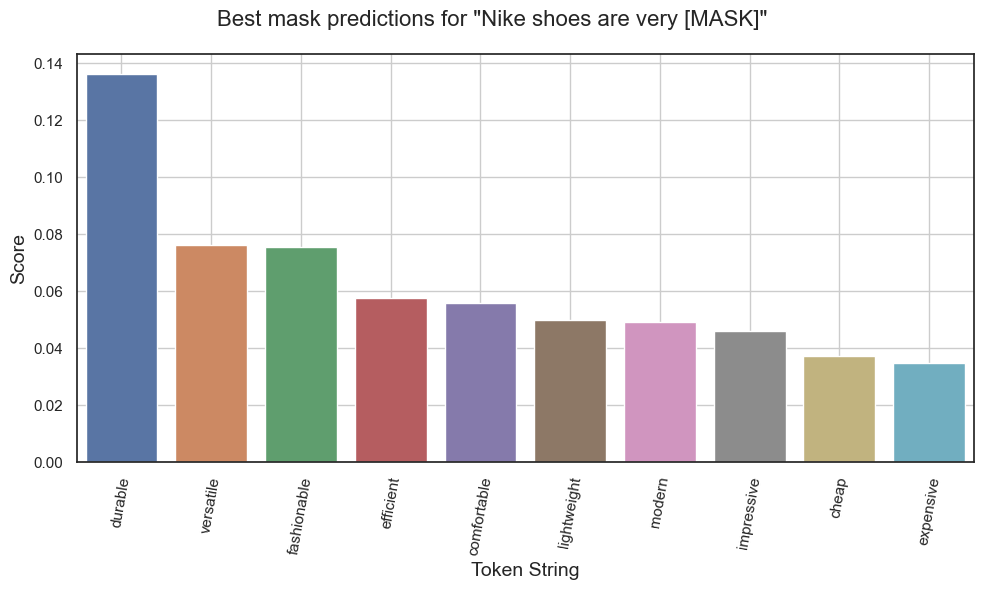
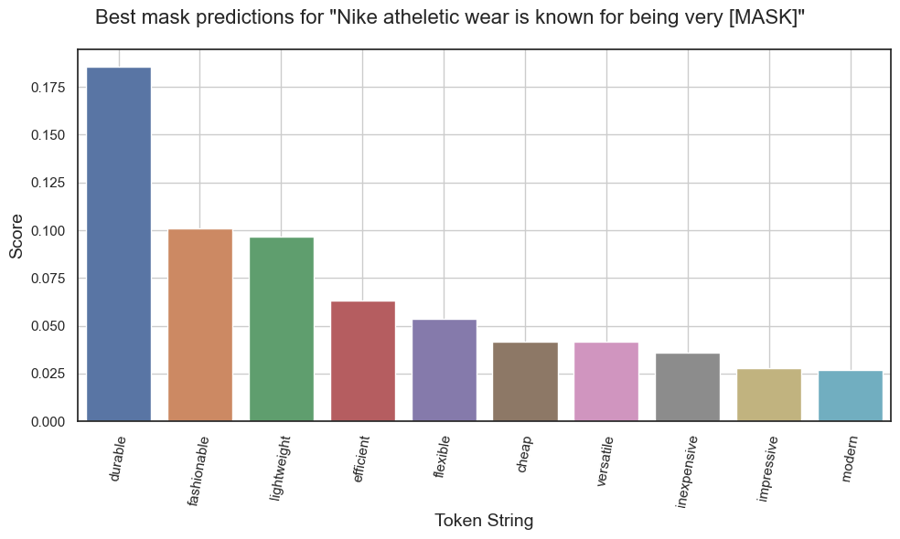
We can create plots for visualizing training/validation loss and perplexity. We can also plot bar charts to visualize the scores of each predicted masked word (higher scores denote higher confidence of the model at respective mask guesses). Here, we plot confidence scores of the Top 10 predictions of the model for each of the chosen testing sentences.
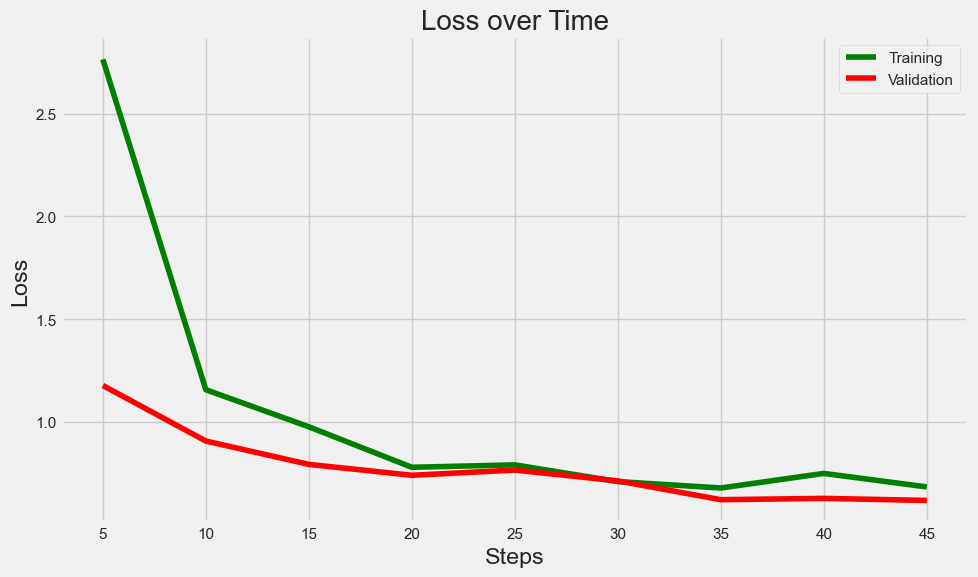
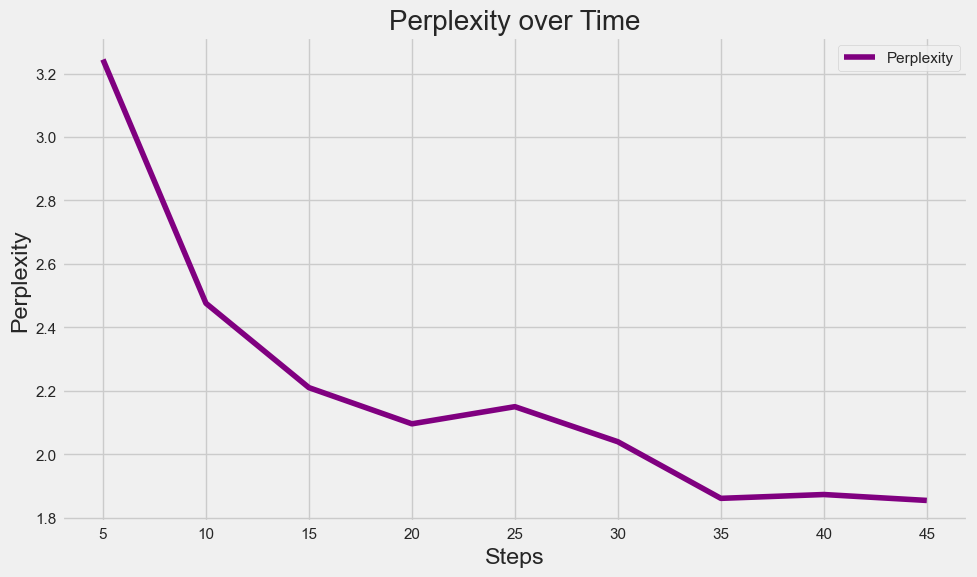
Predictions for "Nike shoes are very [MASK]."
Predictions for "Nike athletic wear is know for being very [MASK]."
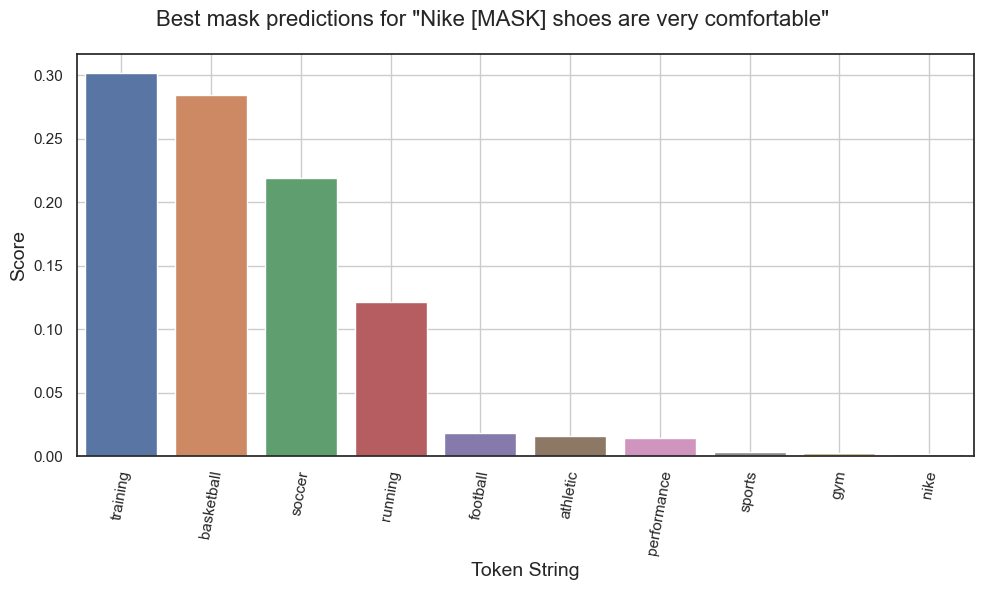
Predictions for "Nike [MASK] shoes are very comfortable."
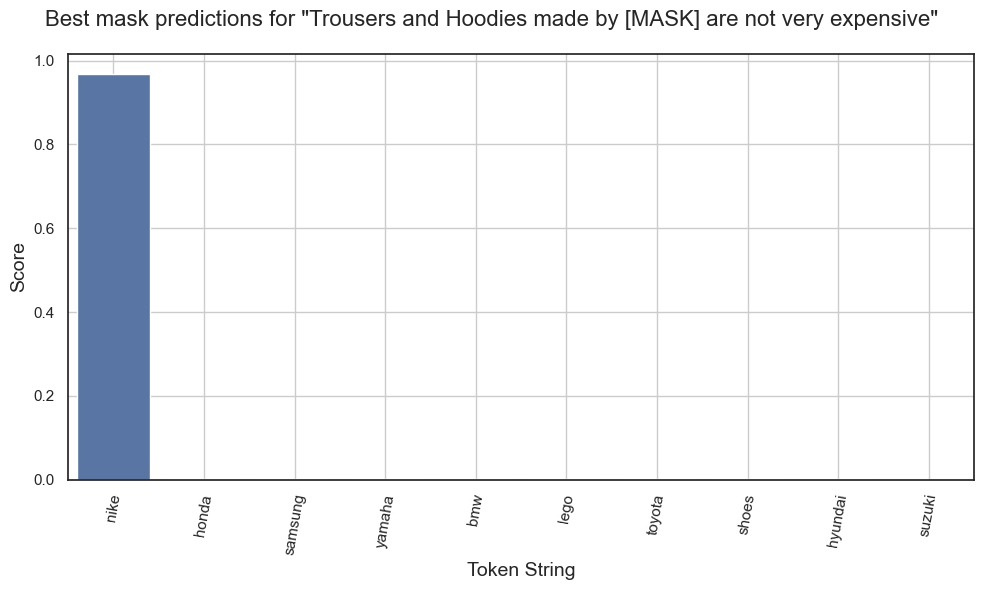
Predictions for "Trousers and Hoodies made by [MASK] are not very expensive."
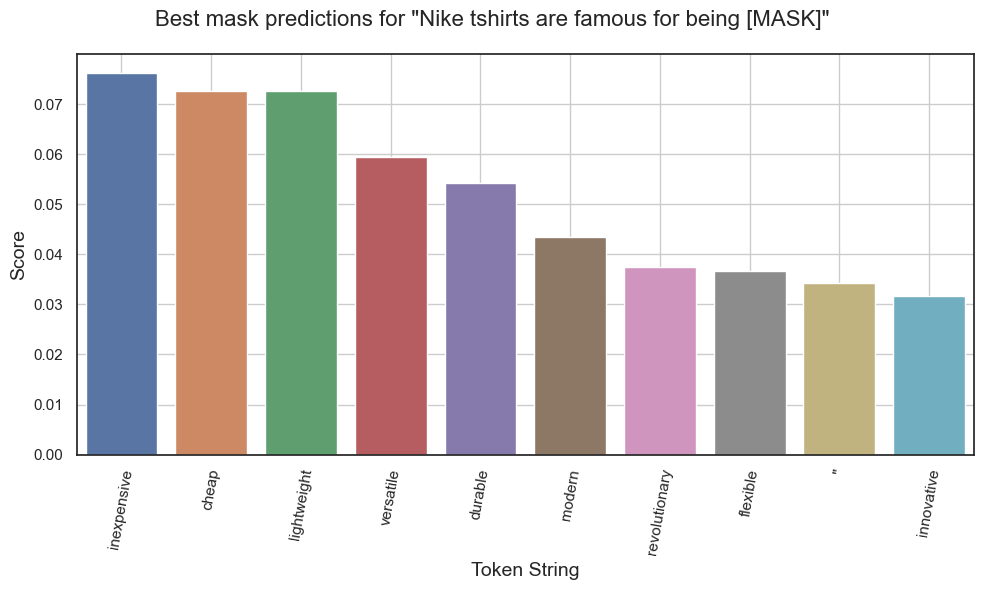
Predictions for "Nike tshirts are famous for being [MASK]."
Last updated
Was this helpful?